
深度学习目标检测:RCNN
什么是目标检测?目标检测主要是明确从图中看到了什么物体?他们在什么位置。传统的目标检测方法一般分为三个阶段:首先在给定的图像上选择一些候选的区域,然后对这些区域提取特征,最后使用训练的分类器进行分类。
- 区域选择
这一步是为了对目标进行定位。传统方法是采用穷举策略。由于目标可能在图片上的任意位置,而且大小不定,因此使用滑动窗口的策略对整幅图像进行遍历,而且需要设置不同的长宽。这种策略虽然可以检测到所有可能出现的位置,但是时间复杂度太高,产生的冗余窗口太多,严重影响后续特征的提取和分类速度的性能。
- 特征提取
提取特征的好坏会直接影响到分类的准确性,但又由于目标的形态多样性,提取一个鲁棒的特征并不是一个简单的事。这个阶段常用的特征有SIFT(尺度不变特征变换 ,Scale-invariant feature transform)和HOG( 方向梯度直方图特征,Histogram of Oriented Gradient)等。
- 分类器
主要有SVM,Adaboost等综上所述,传统目标检测存在两个主要问题:一个是基于滑动窗口的区域选择策略没有针对性,时间复杂度高,窗口冗余;而是手工设计的特征对于多样性没有很好的鲁棒性。
RCNN的检测流程:
RCNN主要分为3个大部分,第一部分产生候选区域,第二部分对每个候选区域使用CNN提取长度固定的特征;第三个部分使用一系列的SVM进行分类。
下面就是RCNN的整体检测流程
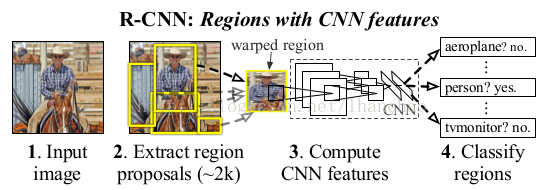
- 首先输入一张自然图像;
- 使用Selective Search提取大约2000个候选区域(proposal);
- 对每个候选区域的图像进行拉伸形变,使之成为固定大小的正方形图像,并将该图像输入到CNN中提取特征;
- 使用线性的SVM对提取的特征进行分类。
